Introduction to High Availability Concepts
A beginner’s guide to high availability concepts, covering failover, redundancy, and monitoring to build reliable systems with minimal downtime.
Complex systems demand constant accessibility to maintain user trust and operational continuity. High availability (HA) ensures applications remain online despite failures, delivering consistent performance through strategic design. By leveraging techniques like failover, redundancy, and proactive monitoring, teams can build resilient infrastructure that minimizes downtime and supports reliability goals. This approach aligns with SRE principles, fostering systems that thrive under pressure while meeting user expectations.
Understanding High Availability
High availability focuses on keeping systems operational with minimal interruptions, often measured as uptime percentage (e.g., 99.9% equates to less than 9 hours of downtime annually). Critical applications, such as those in finance or healthcare, require HA to avoid costly outages. Strategies like fault tolerance and redundancy eliminate single points of failure, ensuring seamless performance even when components fail.
Implementing Failover and Fault Tolerance
Failover mechanisms enable rapid recovery by switching to backup components during failures. For instance, an active-passive setup uses a load balancer to direct traffic to a primary server, with a secondary ready to take over if health checks fail. Fault tolerance designs systems to function despite issues, such as using redundant hardware to prevent disruptions. These techniques ensure reliability by maintaining service continuity.
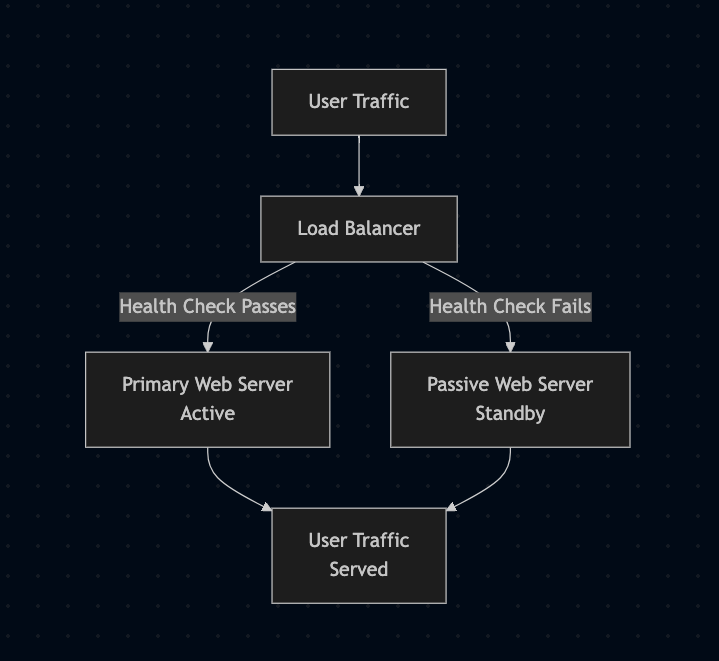 Failover setup with primary and secondary servers
Failover setup with primary and secondary servers
Leveraging Redundancy
Redundancy duplicates critical components to enhance reliability. Examples include running multiple servers across regions or replicating databases for data durability. While effective, redundancy increases complexity and costs, requiring teams to balance these factors against system requirements. Properly implemented, it strengthens HA by mitigating risks of failure.
Monitoring for Reliability
Monitoring is essential for HA, detecting issues like error spikes or slow response times before they impact users. Tools like Prometheus and Grafana track key metrics, triggering alerts for anomalies. For example, a high error rate might prompt a failover, maintaining service availability. Continuous monitoring supports proactive reliability, aligning with SRE observability practices.
Benefits and Challenges
High availability offers significant advantages, including user trust and operational stability. Failover and redundancy reduce downtime, while monitoring enables swift issue resolution. However, challenges include managing the complexity of redundant systems and ensuring cost-effective designs. Teams must carefully plan to maintain reliability without compromising efficiency.
Conclusion
High availability is a cornerstone of resilient systems, combining failover, redundancy, and monitoring to deliver reliable performance. These techniques, rooted in SRE principles, ensure systems remain accessible under stress, supporting seamless user experiences. As infrastructure scales, adopting HA strategies empowers teams to achieve operational excellence and maintain reliability in demanding environments.