Incident Management and Escalation Handling: Keeping Systems Reliable
A guide to structured incident management and escalation for SRE and DevOps teams, with a focus on reliability and best practices.
When a critical system fails, every second counts. Incident management provides a structured framework to transform chaos into a controlled process, enabling SRE and DevOps teams to identify, respond to, and resolve issues efficiently. By minimizing downtime and learning from failures, this approach strengthens system reliability, often preventing user impact. Widely recognized as essential in the industry, it fosters confidence in operational capabilities and maintains robust systems.
Escalation Handling Procedures
Escalation ensures incidents do not stagnate by connecting responders with the right expertise when needed. Here’s how it typically functions:
- When to Escalate: Escalation becomes necessary when an issue demands specialized skills or affects multiple systems. For example, a database failure impacting several services might require senior engineers or input from various teams. Severity levels often guide this process. Using a P0 to P4 scale, a P0 incident (e.g., complete outage) demands immediate escalation, while a P4 (e.g., minor bug) might be handled by the initial responder.
- How to Escalate: Predefined escalation paths, such as from an on call engineer to a team lead or engineering manager, help streamline the process. Tools like Slack or incident bridges, paired with clear documentation, enhance coordination.
A typical escalation matrix might look like this:
- L1 (On Call Engineer): First 30 minutes.
- L2 (Team Lead): If unresolved after 30 minutes.
- L3 (Engineering Manager): If business impact exceeds a predefined threshold, such as 10,000 dollars per hour.
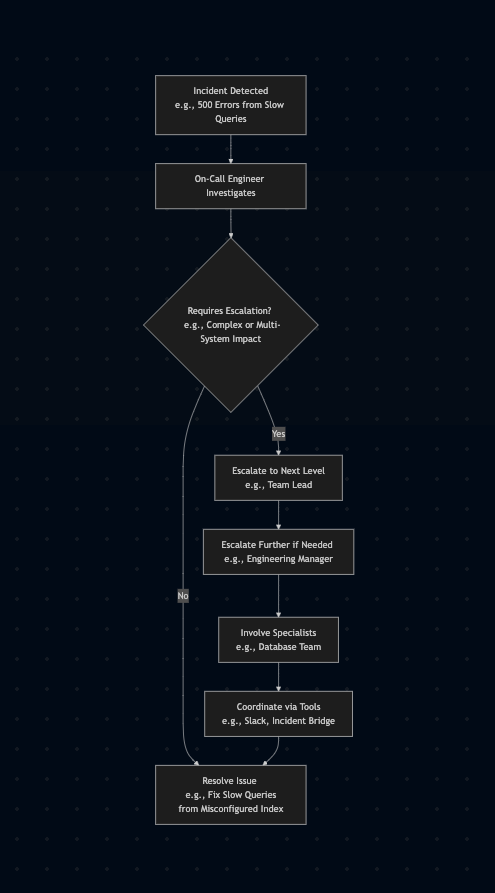 Flowchart showing a typical escalation path during an incident.
Flowchart showing a typical escalation path during an incident.
Hypothetical Scenario: Imagine a service facing widespread 500 errors caused by slow database queries during a busy period. An initial responder investigates but struggles with the underlying performance problem. Escalating to a database specialist uncovers a misconfigured index, resolving the issue faster than a prolonged solo effort.
Best Practices for Effective Incident Response
Certain strategies are commonly recommended for successful incident response:
- Clear Communication: A dedicated channel, with an assigned individual updating both team members and stakeholders, keeps everyone aligned.
- Predefined Roles: Assigning an Incident Commander to oversee operations and a Scribe to log actions minimizes confusion during high pressure moments.
- Post-Incident Reviews: Blameless retrospectives help teams analyze failures and identify preventive measures for the future. These postmortems focus on learning, not blame, encouraging open discussion about what went wrong and how to improve. Teams might create a timeline of events, pinpoint root causes, and define action items, which should then be tracked to ensure implementation.
- Effective Alerting: Alerts should be tuned to highlight actionable issues, keeping the signal to noise ratio low. This ensures teams address genuine problems without being overwhelmed by irrelevant notifications.
Example: Consider a scenario where a memory leak gradually slows a system. Properly calibrated alerts could detect this early, prompting a service restart before users experience disruptions.
Tools and Technologies
Tools that are standard in the industry can significantly streamline incident response. Solutions like PagerDuty and Opsgenie integrate with monitoring systems to automate alerts and notify appropriate personnel swiftly. For example, they can pull metrics from Prometheus for system health insights or use Datadog for broader observability, ensuring timely notifications. Collaboration platforms like Slack enable real time coordination during incidents. These technologies are known to reduce mean time to resolution (MTTR), a critical metric when rapid recovery is essential. Teams might also track mean time to detect (MTTD) to measure how quickly issues are identified, or monitor incident frequency to assess system stability over time.
Conclusion
Structured incident management and escalation handling are vital for upholding system reliability and user satisfaction. By adopting clear processes, refining alerts for relevance, and utilizing effective tools, teams can turn potential crises into manageable events. As systems increase in complexity, these practices grow ever more important to operational success, reflecting widely accepted principles in SRE and DevOps.